 Documentation
Documentation
TTS system overview¶
Techmo TTS is a modern speech synthesis system that uses advanced machine learning and pattern matching algorithms to transform text into a high-quality speech signal. The way the speech signal is generated can be further controlled using SSML (Speech Synthesis Markup Language) tags. Communication with the system is provided by interfaces using the gRPC (and optionally MRCPv2) protocol. For high scalability and easy integration, the Techmo TTS service is distributed as a Docker image.
A single instance of the service can support up to 100 simultaneous sessions (depending on the machine’s performance), in case of higher demand multiple instances can be used in a Kubernetes cluster.
The produced audio can be streamed to the client, allowing the system to remain highly responsive even when synthesizing long messages. Further improvements in processing time can be achieved by using the built-in cache system.
System requirements¶
Techmo TTS requires an operating system that supports docker containerization (Docker Engine version 1.13.1 or newer). The program can be run in a virtual environment, but it is not obligatory.
In many practical uses such as helplines and voice assistants, a significant amount of sentences or their segments are played repeatedly (same greetings, marketing information, clauses in every conversation). For this purpose, the system uses a cache mechanism, that reuses ready-made audio files for entire sentences or their segments. It allows to highly reduce CPU consumption.
System architecture¶
The Techmo TTS system operates in a client-server architecture. The TTS service runs inside a docker container, providing a single selected port for communication with client applications via an API in the gRPC protocol. All external resources, (voice models, definitions of phonetic mappings and text normalization rules, pronunciation lexicons, etc.) are mounted to the container as a docker volume from the local file system, which allows users to easily make detailed changes to the service configuration. However, for immutable configurations, resources can optionally be embedded directly into the image.
The main system components and dependencies are shown in the following diagram:
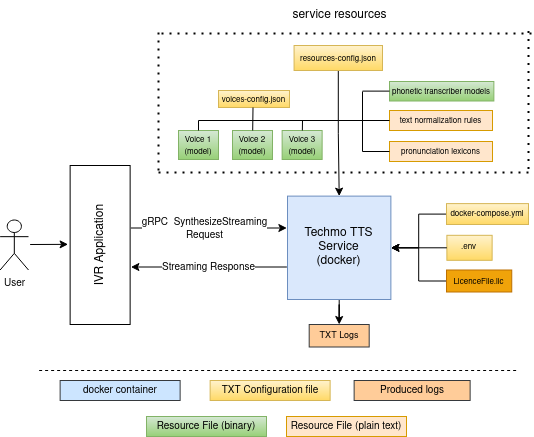
Native service API is based on gRPC framework. In addition, to integrate with the IVR software, you can use an additional proxy service. This proxy service facilitates communication with the TTS service via the MRCPv2 protocol. In such a case, the proxy service runs on a separate Docker container, is independently configured, and produces its own logs.
Depending on the selected licensing mode, the TTS service can use a local licence file or connect to a remote licensing service.
Directory structure of the deployment package¶
The Techmo TTS is provided as a *.tar.gz. package containing the docker image along with all the necessary resources.
The content of the sample TTS DNN CPU package is presented below:
techmo_tts_dnn_3.1.0
├── data
│ └── logs
├── docker-compose.yml
├── docker-image
│ └── techmo-tts-dnn-cpu-service-3.1.0-image.tar.gz
├── .env
├── generate-licence-info.yml
├── licence
│ └── TechmoTTS.lic
├── resources
│ ├── lexicon_pl.xml
│ ├── lexicons-config.json
│ ├── masza
│ │ └── masza.voice
│ ├── michal
│ │ └── michal.voice
│ ├── resources-config.json
│ ├── rules_pl.txt
│ ├── runtime-limits-config.json
│ ├── tables_pl.fsm
│ └── voices-config.json
└── tls
The deployment package consists of:
service docker image in *.tar.gz format (
techmo-tts-dnn-cpu-service-X.Y.Z-image.tar.gz)docker-compose.yml- main compose file to start docker servicegenerate-licence-info.yml- additional compose file for licence data generation.env- service configurationresources- a directory containing service resources:one or more voice models (a binary files with the
.voiceextension)phonetic transcription models, one per language (e.g.
tables_pl.fsm)word inflection definitions, one per language (e.g.
rules_pl.txt)optional resources such as pronunciation lexicons and predefined recordings
configuration files:
resources-config.jsonvoices-config.jsonlexicons-config.json(optional)runtime-limits-config.json(optional, recommended)
licence- an empty directory where the licence file or the remote licensing configuration will be storeddata/logs- an empty directory, where the service logs will be storedtls- a directory where TLS certificates should be placed if encrypted connections are used
To load docker image locally use command:
docker load -i techmo-tts-dnn-cpu-service-3.1.0-image.tar.gz
(in the command above use the actual version of service image)
When image loading completes successfully, a message similar to this one is printed:
Loaded image: techmo-tts-dnn-cpu-service:3.1.0